
This week is one of the most important of the year for the artificial intelligence (AI) sector.
It’s the week that the most valuable semiconductor company in the world — NVIDIA — holds its flagship conference, NVIDIA GTC.
The very first conference was held back in 2009.
For years, the focus tended to be on GPU semiconductors, 3D graphics, and gaming applications…
GTC stands for the GPU Technology Conference, but the conference has evolved to be much more than that.
I remember at the NVIDIA GTC in 2015 when NVIDIA announced its NVIDIA Drive technology platform.
It was a full-stack hardware and software platform, upon which automotive manufacturers could build and test their own autonomous driving technology.
It was such a smart strategy.
Rather than just telling auto manufacturers, “we have great GPUs, and they can be used for autonomous driving,” NVIDIA built an integrated hardware and software system that could get auto manufacturers off the ground and running with something already working.
That was the real inflection point for NVIDIA emerging as a leader in AI technology.
It was when the research and development focus shifted hard… towards machine learning and artificial intelligence. The gaming and graphics business was still there, but it was clear that the growth explosion was happening in AI… and NVIDIA was the one company pushing the outer limits of AI-specific semiconductor technology.
This year will be no different.
NVIDIA’s GTC will be all about AI. But I’m seeing another major shift happening in the industry.
The hot topic this year is quickly becoming something called inference.
Inference is a related, but different, topic than the large language models (LLMs) that we’ve been tracking in Outer Limits.
An easy way to think about it is once we have a trained AI model, that model can be fed new information (voice, video, data) and make a prediction or a decision to take action based on that new information.
It’s similar to the way we humans process information.
Our current “model” of the world is based on everything that we’ve learned in our lifetimes. When we receive new information that requires us to process and decide the best course of action, we are inferring.
AI does something similar… it’s just software running on powerful semiconductors.
But the semiconductors that are optimized for inference are different than the kind used to train these massive, large language models (LLMs) like Gemini Pro (Google), LLama 2 (Meta), Claude 3 Opus (Anthropic), or GPT-4 (OpenAI).
The LLMs are trained on the workhorses of artificial intelligence: graphics processor units (GPUs), designed by either NVIDIA or AMD.
Inference applications, however, are a different beast, which leads us to a must watch company — Groq.
Groq makes what it calls a language processing unit (LPU), which is a semiconductor that is at the heart of Groq’s inference technology.

What’s unique about Groq’s LPUs is that they are a single core architecture with memory on board… with the ability to auto compile entire large language models with basically instant access to anything in its memory.
Why is this so important? Why does it matter?
Technology like what Groq has built is the key to building natural human-to-AI interactions.
Groq’s LPUs enable low latency (low response delay) interactions with an AI that feel more like a very responsive discussion or chat exchange. This technology will be critical to Manifested AI.
In the last few weeks, Groq’s technology has been recognized as a breakthrough in artificial intelligence. Its latest technology was benchmarked against other industry players, and the competition wasn’t even close.
It’s easiest for us to understand the radical performance advantage by looking at a few benchmark charts.
Below is a chart of throughput versus price. Throughput is measured in how many tokens are output per second. A token in artificial intelligence can represent a word, part of a word, punctuation, or a short phrase.
In the chart below, the ideal place to be is in the upper left quadrant. The optimal performance is high throughput at a lower cost.
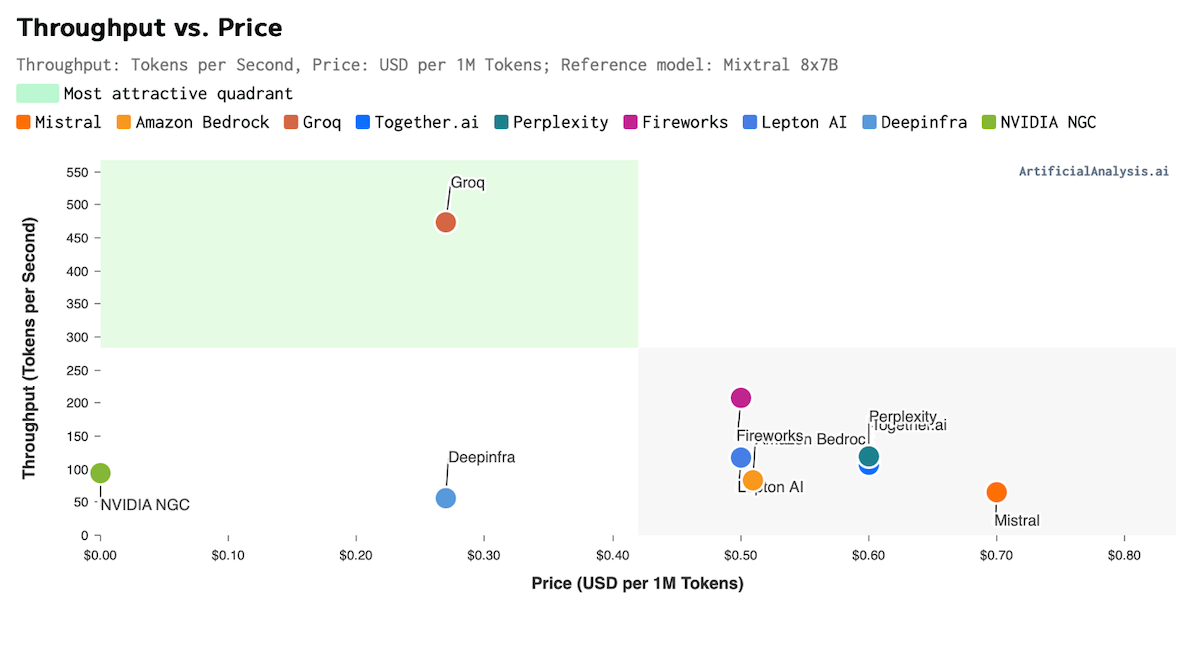
As we can see above, no other company was even close to Groq. It has one of the lowest costs for running inference, and the highest throughput… by many multiples compared to anyone else.
If we loosely generalize that a token is equal to a word for simplicity, an AI model running on Groq is capable of outputting more than 450 words a second.
And with regards to latency (delay), the results are equally impressive.
Below is a chart of latency, specifically the time it takes to output information after an inquiry, versus throughput. Naturally, low latency and high throughput is the goal (lower right quadrant).
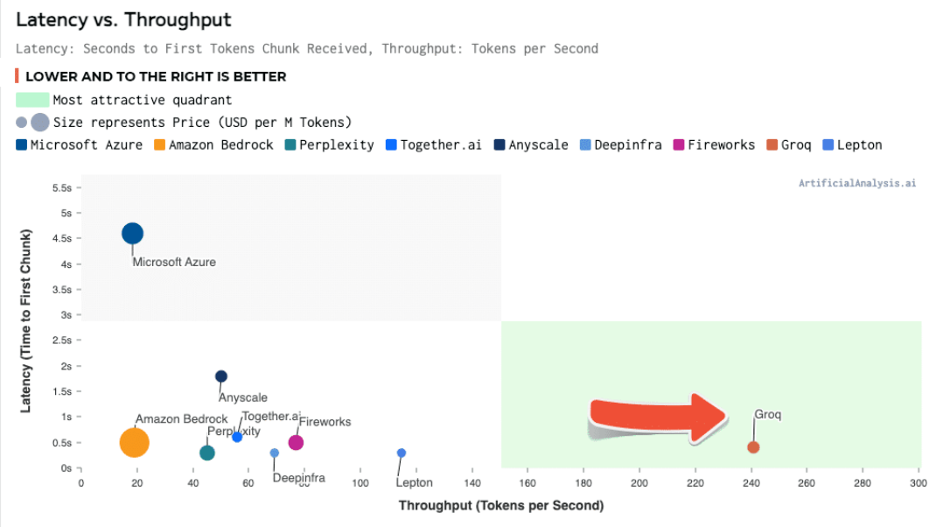
Again, Groq is in a category of its own. Its latency was less than half a second, and its throughput was more than twice that of its closest competitor.
And no matter which benchmark was run, Groq came out on top.
Below is an analysis of various companies running Meta’s 70 billion parameter LLama-2 large language model.
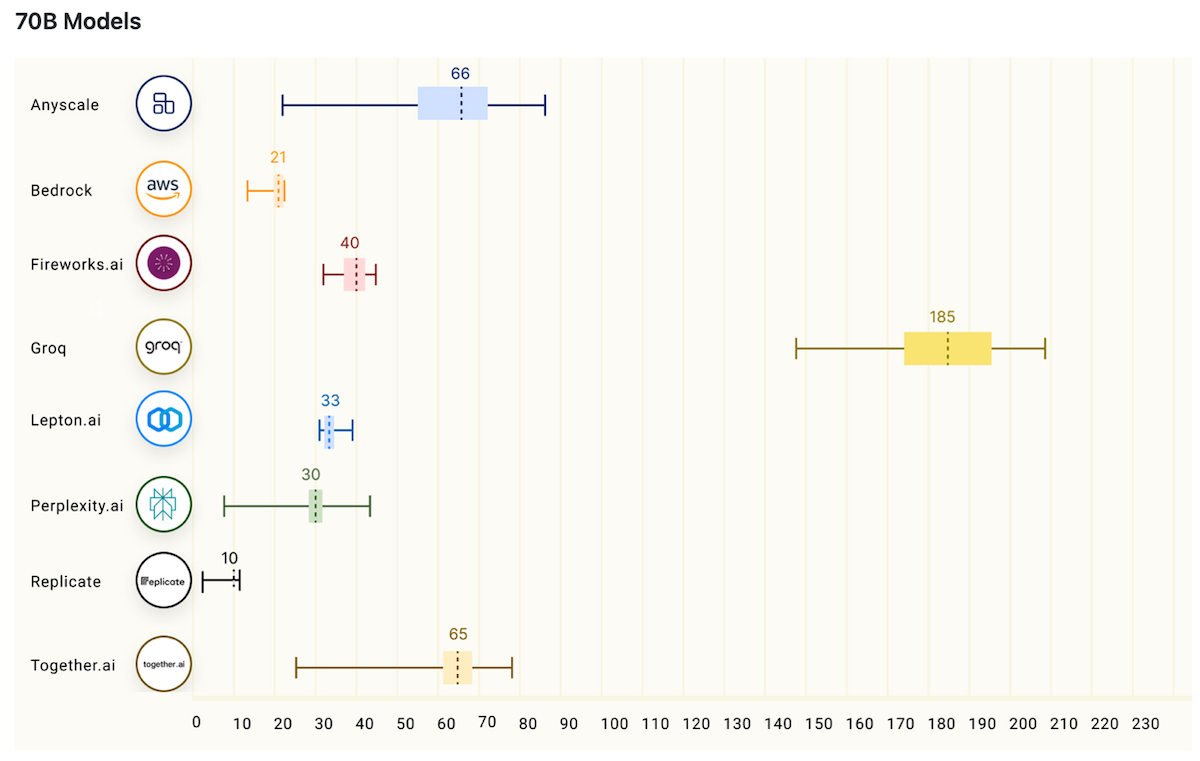
Groq, seen in the middle yellow, was again an outlier.
The above benchmark analyzed an input of 550 tokens and the fastest output of 150 tokens. The numbers above are a measure of output tokens throughput, which is calculated by dividing the output tokens by end-to-end time.
In short, Groq outperformed all competitors anywhere between 3x-18x.
Whenever we’re looking at new technologies, when we see performance advantages like this, we know that the company has something special. It’s a huge jump in performance — not just something like a 10% performance improvement.
So what does this mean to us?
Companies will be able to take their trained AIs and run them on Groq hardware, which will result in the ability to speak with an AI and have a normal discussion.
There won’t be any awkward delays after asking a question — just a quick response, as if we were speaking with someone we know.
The immediate applications will be for any AI chat bots, digital personalized assistants, customer service, sales, and any kind of educational application.
Lightning fast inference is the key to Manifested AI. It’s what will make our interactions with an AI, either online or when we’re speaking with a robot, seem natural, smooth, and human-like.
Groq is currently a private company that is transforming the landscape for inference.
It’s a company to watch, and now an acquisition target.
And it is also the kind of company that I look for when researching private investments for my subscribers. If there are any founders out there that have breakthrough technology like Groq, I’d love to talk to you. You can reach me right here.
We’ll be watching closely to track not only Groq’s technology, but who’s investing, if it gets acquired, or whether or not it can remain independent and go public.
Welcome to the Outer Limits with Jeff Brown. New reader? We encourage you to visit our FAQ, which you can access right here. You may also catch up on past issues right here in the Outer Limits archive.
If you have any questions, comments, or feedback, we always welcome them. We read every email and address the most common threads in the Friday AMA. Please write to us here.